
Ship AI agents
only when they truly
generalize.
Verifiable Labs checks whether a candidate agent really improves beyond visible tests, then returns a SHIP, BLOCK, or LIMIT decision with redacted evidence.
Built to sit above your existing agent stack.
Agent Release Gate
Agent Release Gate — proof that your agent truly improves.
Every agent update can look better on visible tests. Verifiable Labs checks whether the improvement holds before it reaches users.
Connect a baseline and candidate agent workflow. Challenge the candidate beyond visible cases, diagnose where it fails, improve the update, and gate whether it should ship, be blocked, or be limited before production.

CHALLENGE BEYOND VISIBLE TESTS
Run candidate updates through hidden, out-of-distribution, adversarial, and failure-seeking scenarios before they reach users.
DIAGNOSE WHAT FAILED
Find where an agent update breaks across prompts, workflows, tools, retrieval behavior, model choices, and guardrails.
IMPROVE THE CANDIDATE
Turn failure signals into better agent updates before release, instead of treating evaluation as a final scorecard.
SHIP ONLY WHAT HOLDS
Gate the improved candidate with a clear decision — SHIP, BLOCK, or LIMIT — backed by a Generalization Card.
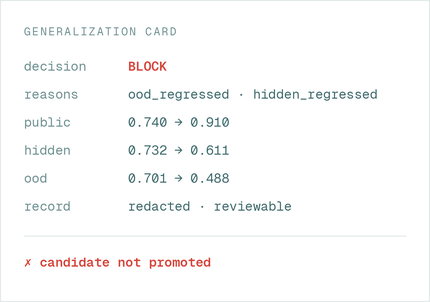
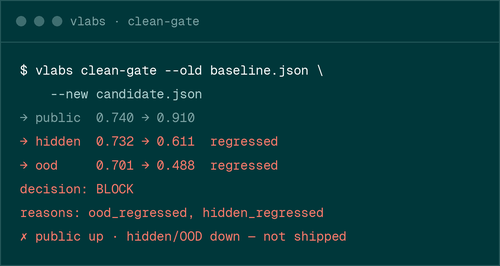
Highest public score ≠ promotion.
Most eval tools show scores. Verifiable Labs gates release decisions.
WITHOUT A RELEASE GATE
- Visible tests pass
- Public score improves
- Hidden failures go unseen
- Overfit behavior slips through
- Teams ship on incomplete evidence
- Baseline and candidate are compared
- Hidden and OOD checks run
- Failure signals are diagnosed
- Decision returns: SHIP, BLOCK, or LIMIT
- Evidence is recorded for review
Every agent update should earn its release.
A release workflow for every agent update.
CHANGE
Submit a candidate prompt, workflow, model, tool-policy, retrieval, or guardrail update.
CHALLENGE
Test the update beyond visible cases with hidden, OOD, adversarial, and failure-seeking scenarios.
IMPROVE
Use the failure diagnosis to refine the candidate before release.
GATE
Ship, block, or limit the update based on whether the improvement holds.
Built for teams shipping AI agents

Agent product teams
Review prompt changes, model swaps, workflow updates, and guardrail changes before they affect users.
Watch demo →
AI platform teams
Add a release gate between experimentation, evaluation, and production deployment.
Book a demo →
Enterprise AI teams
Create a repeatable review process for agent changes without exposing private data or evaluation content.
Talk to us →Demo
Watch the gate block an update that overfits visible tests.
A candidate improves its visible score, but fails hidden/OOD checks. Verifiable Labs blocks the release before production.
$ pip install "vlabs-sdk==0.0.2"$ vlabs clean-gate --old examples/demo/baseline.json \--new examples/demo/candidate.jsoncandidate → SHIP$ vlabs clean-gate --old examples/demo/baseline.json \--new examples/demo/candidate_overfit.jsonoverfit candidate → BLOCKreasons: ood_regressed, contamination_risk_flagged
- Candidate scores higher on visible tests
- Hidden and OOD checks regress
- Gate returns BLOCK with reasons attached
- No unsafe update reaches users
Security
Private by default. Evidence when needed.
Verifiable Labs is designed to review agent updates without exposing what's private. Public evidence is synthetic/redacted and is not a training dataset — it does not include customer data, hidden evals, gold answers, raw traces, private traps, private engine internals, secrets, or provider keys.
- Redacted Generalization Cards
- Approval-gated exports
- Private evaluation boundaries
- No customer data in public demos
- Designed for security review
Pricing
Pricing that scales with your releases.
Priced by agent release check — the gate you run each time you ship an agent update. Start free; upgrade as you ship more.
Free
$0
For developers testing agent reliability.
- 3 agent release checks / month
- SHIP / BLOCK / LIMIT decision
- Generalization Card (basic)
- vlabs-sdk + clean-gate CLI
- community support
Developer
$99/mo
For builders shipping early AI agents.
- 25 agent release checks / month
- Hidden & OOD checks
- GitHub Action release gate
- Generalization Card
- email support
Team
$499/mo
For AI teams validating agent updates before release.
- 150 agent release checks / month
- Hidden, OOD & adversarial checks
- Contamination + reward-hacking risk scoring
- Custom gate policies & team history
- priority support
Enterprise
Custom
For teams needing private deployment, security, compliance, and custom evaluation contracts.
- Unlimited / custom release checks
- SSO, VPC / on-prem, BYOK
- Custom gates & compliance reports
- Private evaluation boundaries
- SLA & security review
Every plan includes
Certified Audit Reports and private deployment available for enterprise customers.

Improve what fails. Ship what holds.
Bring a baseline and candidate agent workflow. Verifiable Labs will show which updates should ship, which should be blocked, and which need limited rollout.